
Architecture Research and Design: Form Renderer
Problems and Solutions
Recalling information described in “Background Research” and “Technical Research”, and linking the two in one:
| User interface (UI) | Basic HTML and CSS | This will be a web-page without any fancy-looking design features just to illustrate basic function of the features. The design class and component will be added by other teams. |
|---|---|---|
| Connection with the markup | Python and NodeJS | To connect to the file we use BeautifulSoup from Python, and NodeJS Request-Cheerio libraries. This is the only solution that have worked. |
Although it was not mentioned in our initial Background Research requirements, after connecting to the markup file, the data is analysed and sent to a txt-file. This is where we use jQuery to load the content of the txt-file to our HTML. Thus, one more problem&solution is:
| Read txt-file | jQuery | Simplest and easiest solution. |
|---|
Overall Solution
As mentioned in the requirements, this project is a composition of work of our team and team 41. Team 41 will be exporting a markup file, which is not specified in neither what would be the extension of the file produced nor what would be the data that it will be containing. Our team, in return, will receive the file and further display it in a web-format, which allows greater flexibility for further customisation. In order to understand our task, here is a brief diagram explaining the whole idea of the project:
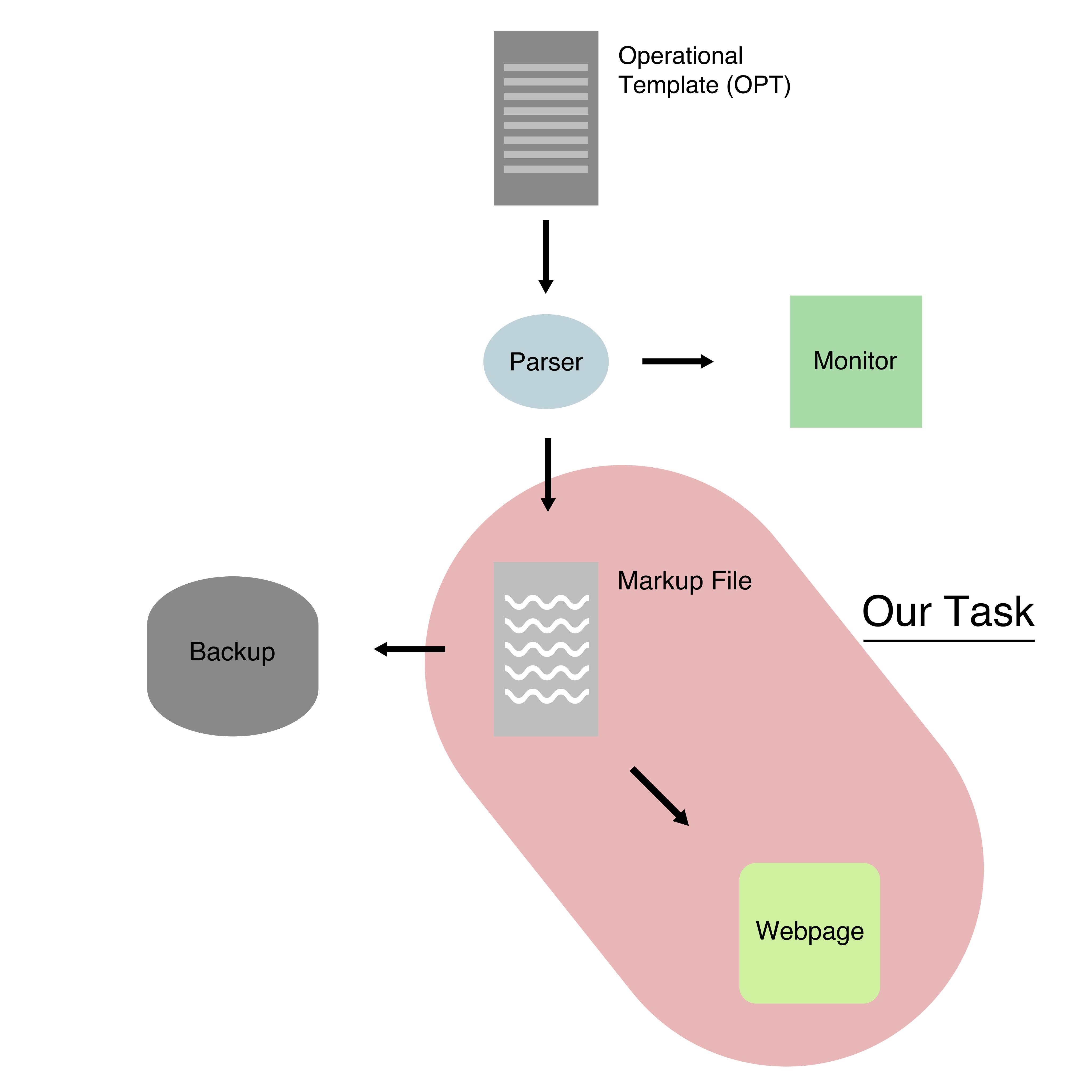
To start with, team 41 is provided with Operational Template (OPT) file which is then analysed through a parser algorithm. One of the future tasks would be to add a 'Monitor' to easily update the data in the file that parser algorithm has produced. However, their current task is just to export the data that parser produces as a markup file. Additionally, one of their tasks is also to find a way to backup the markup file to be able to recover it in case of unexpected loss of data.
The part of the diagram marked in red is our team's task. The general idea is to analyse the markup file provided, be it HTML or XHTML, and to display that data in a friendly manner to the users of the application (the whole diagram is just one function in a large application project). To further illustrate our task in particular, here is a diagram describing the architecture of our code:
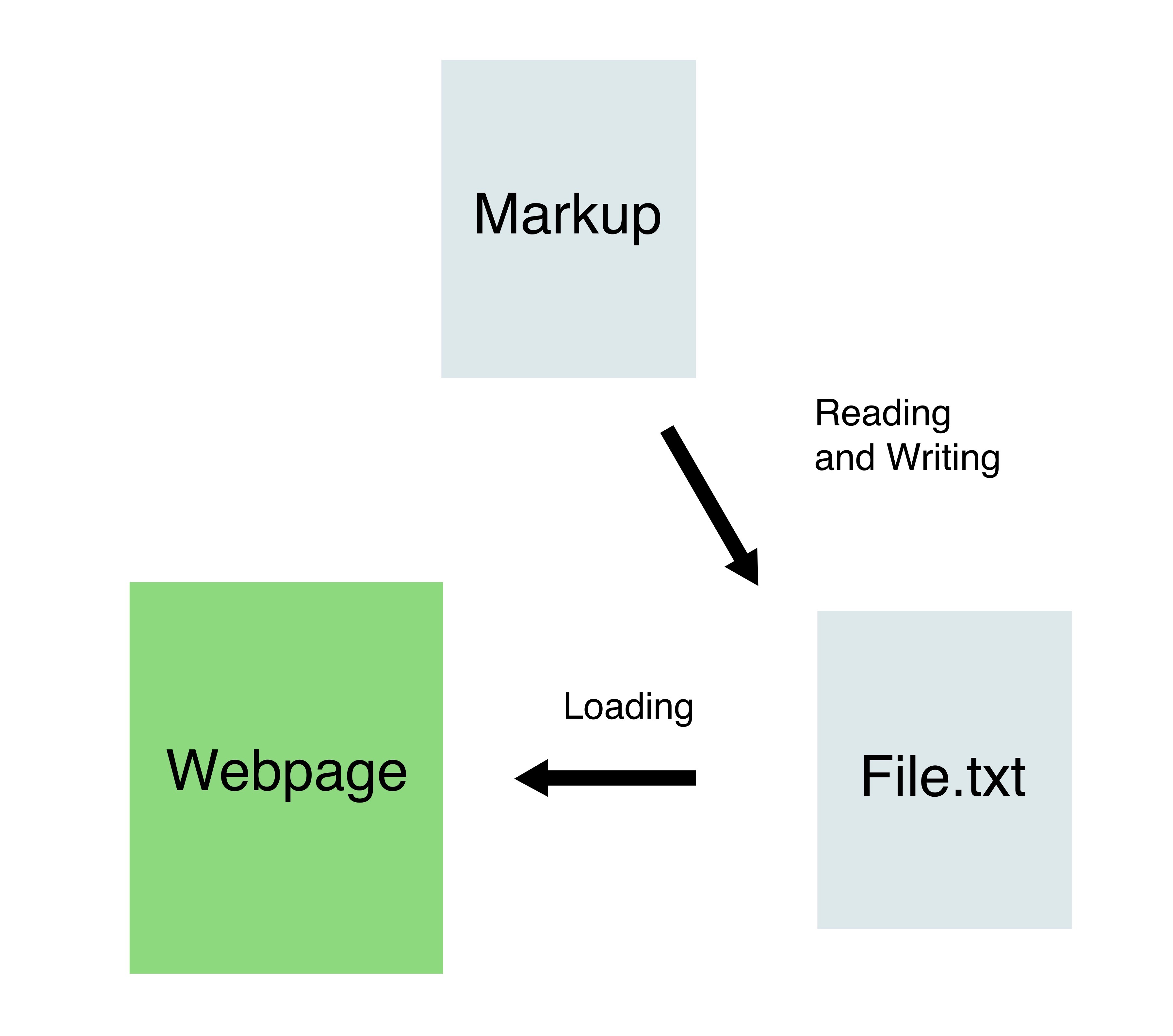
We are using Node.js (Request+Cheerio) to analyse and read the markup file and to export the result as a separate, smaller .txt or .html file. This way, we are breaking the markup file into separate sub-files which can then be loaded to the webpage using jQuery. One of the obvious limitations is that in case a user is retrieving a few bits of information, N, there will be just as many, N number of, additional .txt or .html files created to be separately loaded to the screen. The other solution to the problem would be to read the data and to write it directly to the webpage, therefore having one-to-one relation with the markup and the webpage; however, this also has its own limitations. For example, it would require a separate script to reload only the part of the webpage that is being updated, and due to the fact that the requirements of the webpage (or maybe an application) and the markup are not set by other teams (yet), our team is unable to predict the format and the look of the data and the webpage. Therefore, current solution provides a more universal, though less efficient, approach for the time being.